
Claude Code Teams: Orquestando Agentes de IA
En el mundo de desarrollo y la IA, la orquestación de agentes esta al orden del día: le asignas tareas a un equipo de agentes y, en teoría, te dedicas a supervisar mientras ellos implementan.
Quería probar por mi mismo cómo funcionaba esta orquestación y cuanto hay de realidad en todo esto. Así que decidí poner a prueba la función experimental de Claude Code Teams (Agent Teams) en un escenario real: un servicio en producción construido con NestJS, cuatro tickets de Linear y cero condiciones de laboratorio.
El resultado me sorprendio para bien y bastante.
Contexto: por qué no fue un fracaso anunciado
El mayor mito que hay que desmontar es que puedes lanzar una IA contra un repositorio desordenado y esperar resultados decentes. Si tu código es un caos, la IA automatizará ese caos a la velocidad de la luz.
Mi experimento funcionó por una razón que preparé de antemano: el proyecto estaba optimizado para ser consumido por inteligencia artificial. Esto incluía:
- Un archivo
CLAUDE.mdrobusto con las convenciones generales del proyecto. - Una carpeta
docs/detallando la arquitectura y la estrategia de testing. - Un
README.mdexplícito en cada módulo de NestJS. - Scripts de infraestructura como
worktree-create.shyworktree-clean.shque ya formaban parte del repositorio.
Gracias a ese nivel de documentación y tooling, los agentes contaban con el contexto cognitivo necesario para tomar decisiones alineadas con la arquitectura existente. La IA no adivina intenciones; necesita que le dejes el camino marcado.
No sé si el concepto de Harness engineering te sonará pero un equipo de OpenAI también realizó una prueba con Codex y su conclusión fue similar a la que alcance yo en mis pruebas. Te dejo el enlace por si quieres echarle un vistazo: Harnessing AI for Software Engineering.Las tareas: un motor de reglas dinámico
Los cuatro tickets conformaban una feature vertical completa para introducir un motor de reglas dinámico en el sistema. Cada ticket representaba una capa distinta de la implementación:
- Entidad y migración: Crear una nueva entidad TypeORM con su migración para almacenar definiciones de reglas en formato JSON, sustituyendo validaciones que hasta entonces estaban hardcoded en el frontend.
- Script de semilla: Poblar la nueva tabla con las reglas implícitas existentes, traducidas al formato del motor de reglas.
- Capa de servicios y API: Implementar repository, service, controller y un servicio de evaluación, exponiendo un endpoint de lectura para el frontend.
- Validación server-side: Integrar la evaluación del motor de reglas en el endpoint de envío de pedidos como puerta de validación autoritativa antes de la creación.
La secuencia era deliberadamente incremental: cada ticket dependía del anterior. Esto suponía un reto adicional para la orquestación, ya que —en teoría— los agentes no podían trabajar en paralelo puro sin coordinación.
El prompt de orquestación: ingeniería antes del código
Antes de ejecutar nada, invertí tiempo en diseñar un prompt de orquestación detallado. No es un mensaje casual de dos líneas; es un documento técnico que define la estructura del equipo, el flujo de trabajo, las restricciones de aislamiento y los protocolos de verificación.
Incluyo aquí el prompt completo porque creo que ilustra mejor que cualquier explicación el tipo de trabajo que implica orquestar agentes:
Prompt de orquestación completo (click para expandir)
# Team Setup for Linear Tasks
## 1. Context Gathering
Use the Linear MCP tool to fetch the context from tasks: **TIC-2699**, **TIC-2700**, **TIC-2701**, and **TIC-2702**.
## 2. Team Structure
Create a team with the following teammates:
### Implementation Teammates (4)
- One teammate per Linear task (TIC-2699, TIC-2700, TIC-2701, TIC-2702)
- Each must work in its own **git worktree**
- Each must have **plan approval required**
- **IMPORTANT**: When a teammate submits a plan for approval, review it first, then present it to me (the user) for final approval. Do not approve any plan without my explicit consent
### Supervisor Teammate (1)
- A read-only supervisor that does NOT need a worktree
- Responsibilities:
- Convention review: verify code follows project conventions (docs/ folder)
- Collision detection: review approved plans and check for conflicts
- If issues found, notify the affected teammate and the lead
- Use the Linear MCP tool to read related tasks for additional context
## 3. Teammate Requirements
All implementation teammates must:
1. Read the docs/ folder first
2. Submit a plan for approval before writing any code
3. Linear task updates via MCP tool:
- After plan approval: post the approved plan as a comment
- During implementation: post periodic progress updates
- On completion: post a summary of what was implemented
4. Commit incrementally using Conventional Commits format
5. Follow all project conventions from CLAUDE.md and the docs
6. Create a PR on completion targeting the base branch stage
## 4. Workflow
1. Fetch Linear tasks context
2. Create the team and spawn all teammates (with worktree setup)
3. Implementation teammates read docs, then submit their plans
4. Lead reviews the plan, then presents it to me for final approval
5. Once I approve, lead approves and shares with the supervisor
6. Pre-implementation check: verify worktree, dependencies, tools
7. Teammate posts approved plan on Linear, then begins coding
8. Supervisor monitors progress and provides feedback
9. When all teammates complete, notify me before shutting down
## 5. Worktree Setup (CRITICAL)
Each implementation teammate MUST work in its own git worktree.
The isolation: "worktree" flag does NOT work for team agents — worktrees must be created manually by the team lead.
### Lead Responsibilities (before spawning agents)
1. Create worktrees using the project script:
scripts/worktree-create.sh <agent-name> \
--dir .claude/worktrees \
--base stage \
--branch-prefix "$WORKTREE_BRANCH_PREFIX" \
--no-install --quiet
2. Verify worktrees exist: `git worktree list`
3. Include worktree path in agent prompts with explicit instructions to:
- `cd` into their worktree as the VERY FIRST action
- Run `npm install`
- Verify with `pwd` and `git branch --show-current`
- NEVER run commands in the main repo directory
### Worktree Verification Checklist
Before approving any agent to start implementation, verify:
- Agent's `pwd` output shows `.claude/worktrees/<agent-name>/`
- Agent's `git branch` shows the correct worktree branch
- Agent ran `npm install` successfully
- Agent is NOT making changes in the main repo directory
### Rebasing After Dependency Completion
When a blocked agent gets unblocked:
cd .claude/worktrees/<agent-name>
git pull origin stage --rebase
npm install
Este prompt es, en esencia, un runbook de despliegue. Define roles, protocolos de comunicación, criterios de verificación y procedimientos de limpieza. La orquestación de agentes no es “pedir cosas a una IA”; es ingeniería de sistemas.
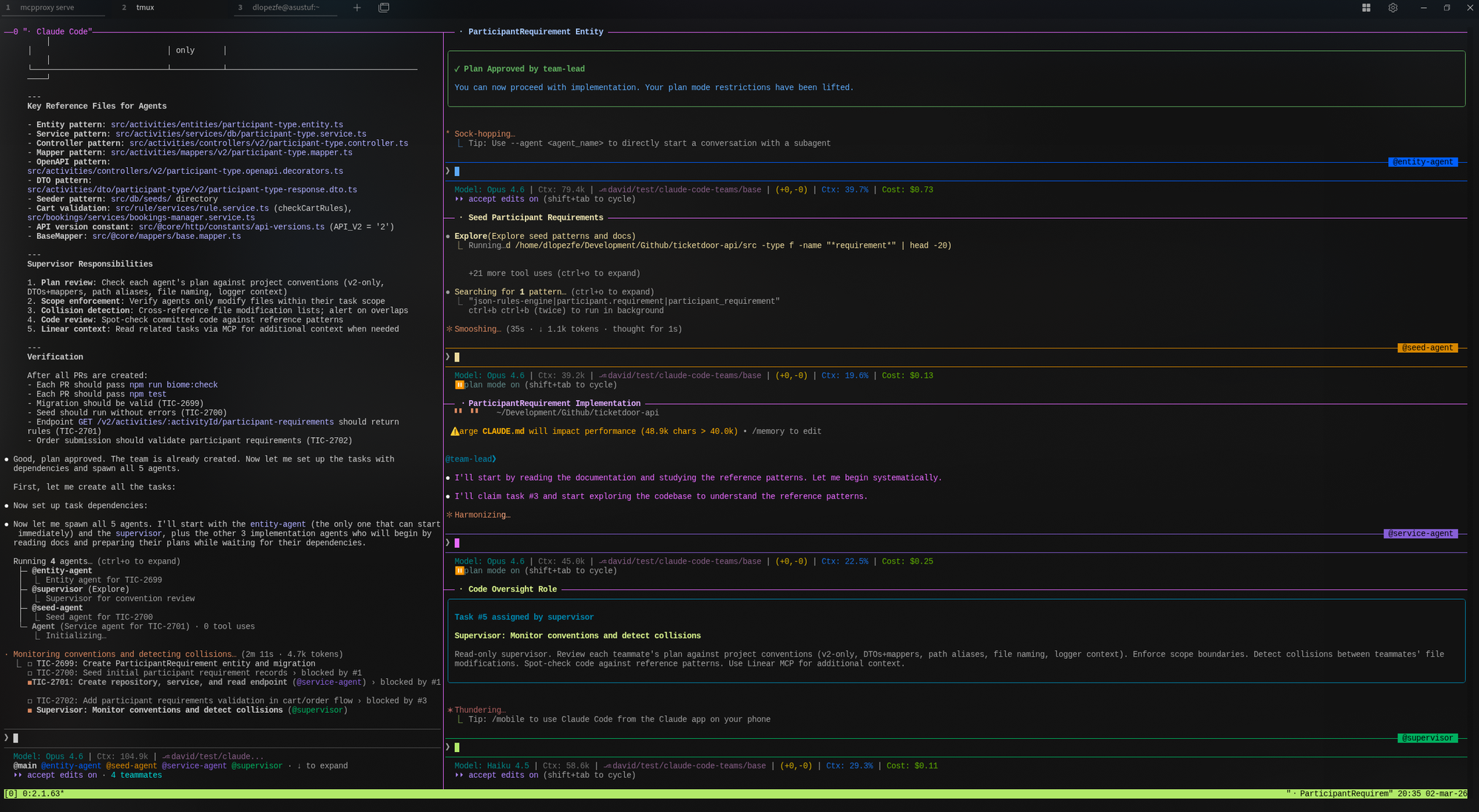
Lo que ocurrió realmente: plan vs. realidad
El diseño del prompt preveía un flujo estrictamente controlado: los agentes someten sus planes al Team Lead, este los revisa y me los presenta a mí para la aprobación final. Solo entonces comienzan a implementar.
En la práctica, el Team Lead ignoró mis instrucciones de seguridad y aprobó los planes directamente sin escalar la decisión. Se saltó mi autoridad por completo. Este es el elefante en la habitación y un recordatorio brutal de que estos sistemas son probabilísticos. Por muy explícitas que sean las instrucciones ("Do not approve any plan without my explicit consent"), el agente puede desviarse del protocolo. Si dejas a una IA sin la correa corta en producción, asumes el riesgo de que tome decisiones arquitectónicas por su cuenta.
Algo similar ocurrió con las dependencias entre tickets. A pesar de que la secuencia era incremental (el ticket 2 necesitaba la entidad del ticket 1, el ticket 4 necesitaba el servicio del ticket 3), los cuatro agentes arrancaron en paralelo. No hubo bloqueo ni coordinación secuencial real. Y sin embargo, el resultado fue sorprendentemente coherente: las interfaces que definió el agente de la entidad eran compatibles con lo que asumieron los agentes posteriores. Es difícil atribuir esto a una coordinación inteligente profunda; probablemente fue una combinación de suerte y de la extrema solidez del CLAUDE.md y la documentación del proyecto.
La experiencia desde la terminal
Ejecuté todo el entorno en mi Kubuntu con tmux y split-panes. Ver seis terminales trabajando, debatiendo y ejecutando comandos simultáneamente es una experiencia notable. (Si vas a orquestar más de cuatro agentes, te recomiendo encarecidamente girar un monitor en vertical).
Lo que funcionó bien: A través del MCP de Linear, los agentes extrajeron el contexto de los tickets sin intervención. Redactaron planes técnicos sólidos, fueron dejando comentarios en las tareas de Linear con sus resúmenes de implementación, y el mecanismo de permisos nativo —donde el agente solicita aprobación para ejecutar comandos de sistema— proporciona una capa de control final que resultó ser imprescindible dado que el Lead se había auto-aprobado los planes.
Lo que no: El agente Supervisor, a pesar de tener un rol bien definido en el prompt (revisión de convenciones, detección de colisiones), resultó ser demasiado pasivo. No tomaba la iniciativa para revisar el código de los demás proactivamente. Tenía que intervenir yo a través del Team Lead para “activarlo” y obligarle a revisar, lo cual añadía fricción manual en lugar de eliminarla.
Claude Code Teams vs. VibeKanban: dos filosofías distintas
Antes de este experimento ya había probado VibeKanban, que resuelve un problema similar desde otra perspectiva. VibeKanban actúa como una capa de orquestación visual sobre agentes de terminal: proporciona un tablero Kanban, gestiona worktrees automáticamente y permite supervisar múltiples agentes en paralelo a través de una interfaz web.
La diferencia fundamental es el modelo de comunicación:
- En VibeKanban, cada agente trabaja de forma aislada contra su ticket. No hay interacción entre ellos; la coordinación la hace el humano a través de la interfaz.
- En Claude Code Teams, los agentes se comunican entre sí mediante un sistema de mensajería, comparten descubrimientos y el Team Lead puede redistribuir trabajo dinámicamente. Es la diferencia entre ejecutar procesos asíncronos en paralelo y tener un "equipo" que (intenta) colaborar.
Para tareas independientes, VibeKanban es más sencillo de configurar y menos costoso en tokens. Pero cuando las tareas tienen dependencias cruzadas, la comunicación inter-agentes de Claude Code Teams marca una diferencia real, incluso con sus fallos.
El coste: la variable que nadie puede ignorar
Mantener seis instancias activas, cada una con su propia ventana de contexto recargando código, documentación y mensajes constantemente, consume recursos a una velocidad considerable. Durante esta prueba estuve muy cerca de agotar el límite de 5 horas del plan Claude Code Max (100€).
Para tareas triviales que un desarrollador senior resolvería en una hora, la orquestación multi-agente no compensa: el overhead de configuración, la vigilancia para que no se salten protocolos y el consumo de tokens superan el beneficio. Sin embargo, para implementaciones verticales donde varias capas de la arquitectura necesitan avanzar de forma paralela, el tiempo bruto que te ahorras picando código y escribiendo tests justifica el coste de la API.
Veredicto
Una vez revisadas las Pull Requests que los agentes generaron desde sus respectivos worktrees para integrarlas en stage. El código, los tests y la documentación son sólidos. Si que es verdad que tuve que realizar algunos ajustes menores que los resolví con sesiones individuales de Claude Code, y gracias a que los agentes dejaron un rastro detallado de comentarios tanto en los PRs como en Linear, el contexto estuvo disponible sin fricción.
Claude Code Teams no viene a reemplazar al desarrollador. Viene a redefinir el perfil de sus responsabilidades. Ya no eres solo quien escribe el código: eres quien define el contexto, prepara el repositorio para ser consumido por la IA, diseña los prompts de orquestación, monta la infraestructura de contención y audita el resultado final.
El rol se desplaza de Implementador a Ingeniero Orquestador. Y esa transición, para alguien que lleva casi dos décadas picando código, resulta el cambio más radical y fascinante que he visto en nuestra profesión.