
DeepSeek lo vuelve a hacer: De MoE a DSA, la nueva era de eficiencia en los LLMs
Imagen de cabecera obtenida de Chat-Deep.
Introducción: El Muro Invisible de los LLMs
En el vertiginoso mundo de la Inteligencia Artificial, a menudo nos maravillamos con el tamaño y la capacidad de los nuevos modelos de lenguaje (LLMs). Sin embargo, detrás de cada avance existe un muro invisible, un desafío fundamental que limita su escalabilidad y accesibilidad: el coste computacional. El equipo de DeepSeek AI parece haber hecho de la demolición de este muro su especialidad.
Primero nos presentaron su modelo DeepSeek-V2 con la rompedora arquitectura Mixture-of-Experts (MoE), una forma inteligente de escalar modelos activando solo una fracción de sus parámetros para cada tarea. Y ahora, lo han vuelto a hacer. Con el lanzamiento de DeepSeek-V3.2-Exp, atacan otro de los pilares que sostenían ese muro: la complejidad del mecanismo de atención.
El Problema de Fondo: La Tiranía de la Complejidad Cuadrática \(O(L^2)\)
Para entender la magnitud de esta innovación, primero debemos hablar del enemigo: la complejidad cuadrática \(O(L^2)\) en el mecanismo de atención de los Transformers.
Desde su concepción, la atención ha permitido a los modelos entender las relaciones entre palabras en un texto. Para ello, cada nuevo token que se procesa debe "atender" a todos y cada uno de los tokens que le preceden. Esto es increíblemente potente, pero tiene un coste.
En términos sencillos, la complejidad cuadrática significa que si duplicas la longitud del texto (el contexto), el coste computacional y el tiempo de cálculo no se duplican, se cuadruplican. Si lo triplicas, se multiplica por nueve. Esto crea un cuello de botella exponencial que hace que procesar documentos muy largos, bases de código enteras o libros sea prohibitivamente caro y lento.
La Solución: DeepSeek Sparse Attention (DSA)
DeepSeek-V3.2-Exp introduce una solución elegante a este problema: DeepSeek Sparse Attention (DSA). En lugar de la atención "densa" (todos contra todos), DSA implementa una atención "dispersa" o "escasa" donde cada token solo atiende a los tokens más relevantes.
¿Cómo lo consigue? La arquitectura se basa en dos componentes principales:
- Lightning Indexer (Indexador Rápido): Este es el cerebro de la operación. Es un componente muy eficiente que, antes del cálculo de atención principal, calcula una "puntuación de índice" \(I_{t,s}\) entre el token de consulta actual y todos los tokens anteriores. Esta puntuación determina la relevancia. Su diseño es clave para la eficiencia, ya que utiliza pocas cabezas y puede ser implementado en FP8.
- Fine-grained Token Selection (Selección Fina de Tokens): Basándose en las puntuaciones del indexador, este mecanismo es puramente selectivo. Recupera únicamente las entradas de clave-valor (
key-value) que corresponden a lastop-k(las 'k' mejores) puntuaciones del índice. En el paper, por ejemplo, mencionan la selección de 2048 tokens clave-valor por cada consulta.
El resultado es que el cálculo de atención principal ya no se realiza sobre toda la secuencia, sino sobre un pequeño subconjunto de tokens relevantes. Esto cambia las reglas del juego, reduciendo la complejidad de la atención de \(O(L^2)\) a \(O(Lk)\), donde 'k' es un número fijo y mucho más pequeño que la longitud 'L' del contexto.
Resultados: Eficiencia Radical sin Sacrificar Rendimiento
Aquí es donde la propuesta de DeepSeek brilla. No se trata solo de una optimización teórica; los resultados son tangibles y, lo más importante, se logran sin un deterioro significativo del rendimiento.
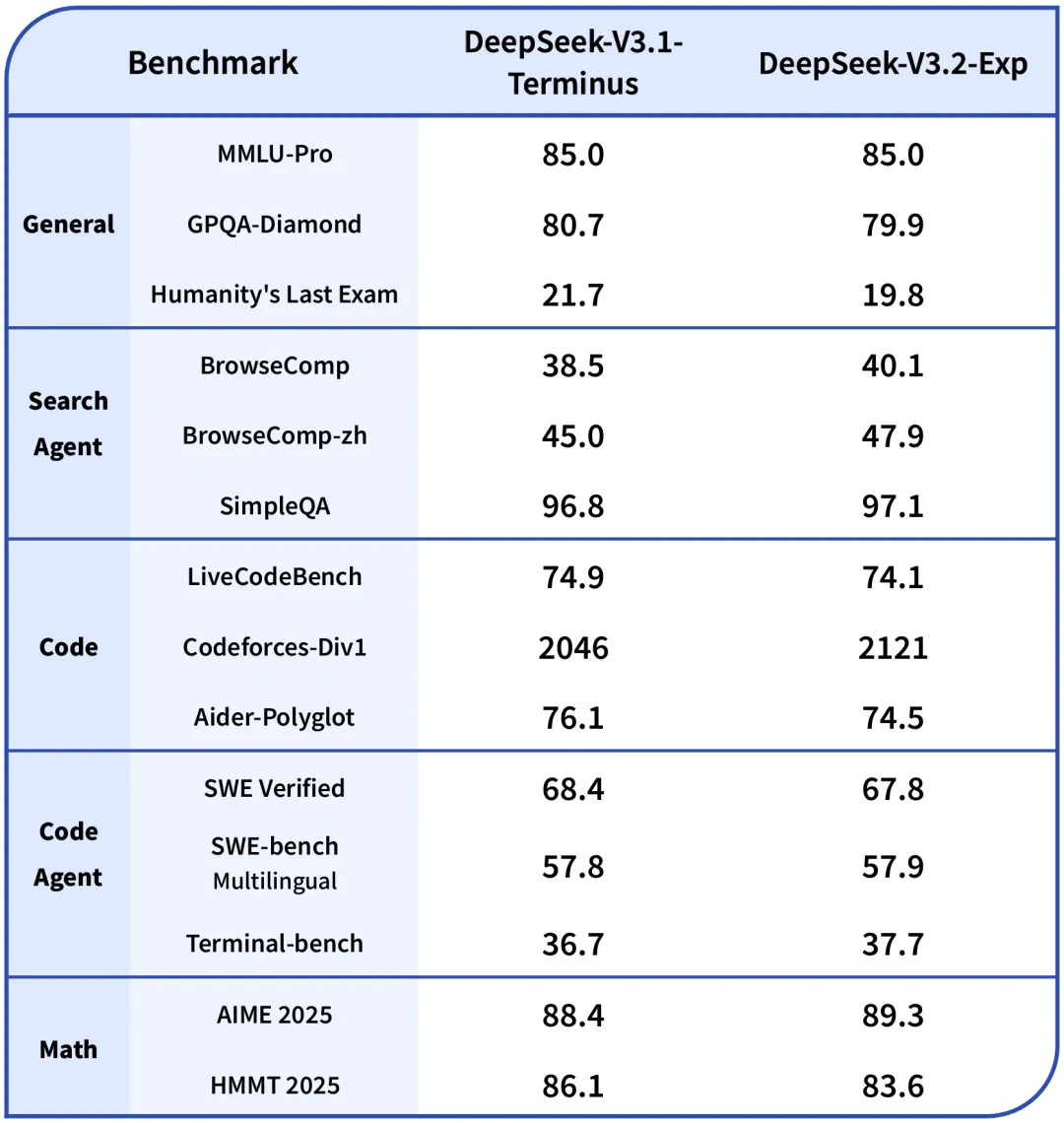
- Rendimiento Equiparable: Las evaluaciones comparativas muestran que DeepSeek-V3.2-Exp no presenta una degradación sustancial del rendimiento en comparación con su predecesor, DeepSeek-V3.1-Terminus. En benchmarks clave como MMLU-Pro, el resultado es idéntico (85.0), y en otros, las variaciones son mínimas.
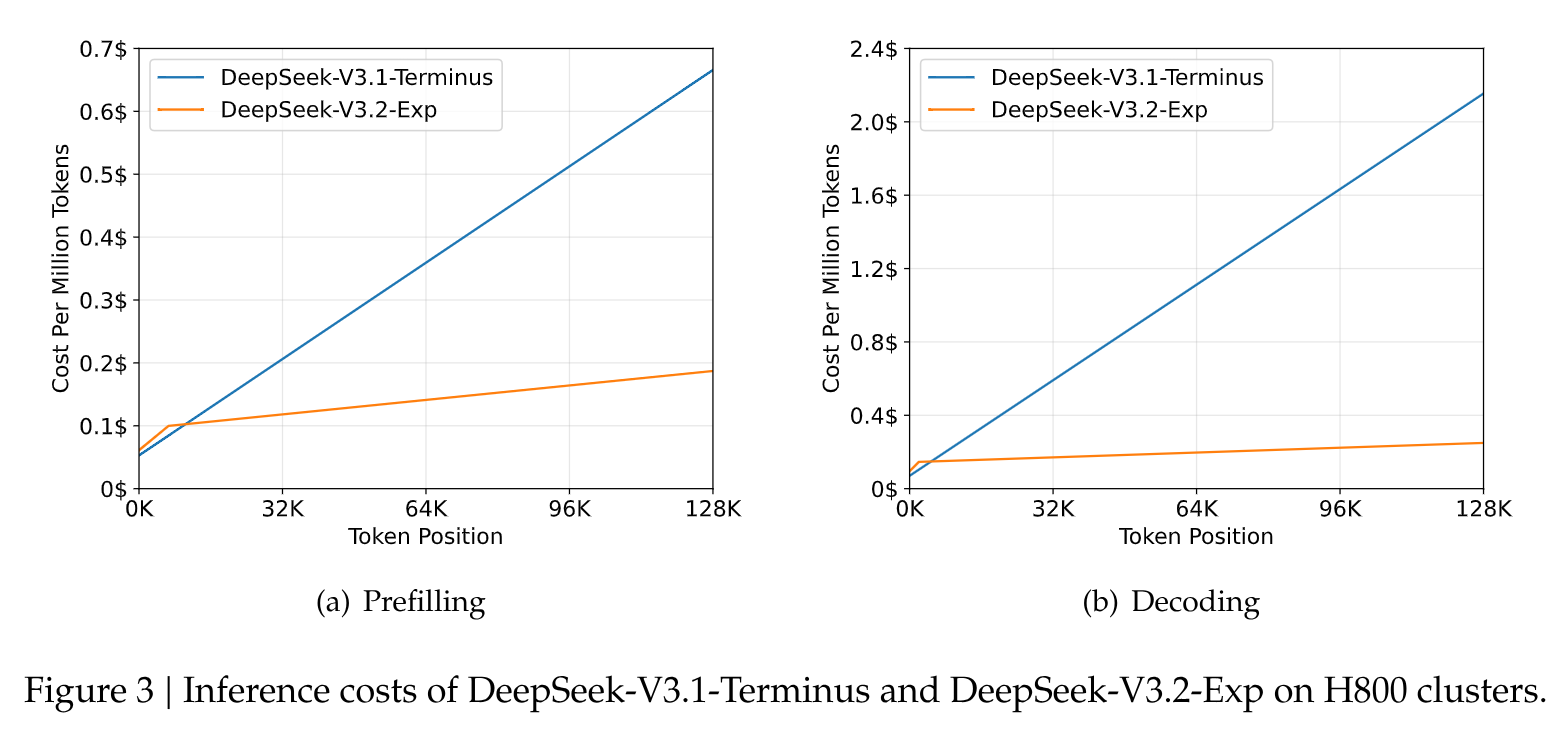
- Reducción Drástica de Costes: La Figura 3 del paper es concluyente. Muestra cómo el coste por millón de tokens, tanto en el prefilling (procesamiento del prompt inicial) como en el decoding (generación de la respuesta), se dispara linealmente en el modelo antiguo a medida que aumenta la longitud del contexto. En cambio, con DSA, la curva de coste se aplana drásticamente, demostrando un ahorro masivo en escenarios de contexto largo.

En su paper puedes ver con más detalle todo su analisis.

¿Qué Significa Esto para el Futuro?
Desde mi perspectiva centrada en la creación de software a medida y la aplicación de IA, este avance no es solo una mejora incremental; es un habilitador.
- La Era de las Arquitecturas Híbridas: DeepSeek nos está mostrando el camino. El futuro no es una única solución, sino la combinación inteligente de arquitecturas eficientes. Imaginaos un modelo que combine la eficiencia de parámetros de MoE con la eficiencia de contexto de DSA. Estaríamos ante una nueva generación de LLMs fundamentalmente más escalables y económicos.
- Nuevas Fronteras de Aplicación: Con costes de contexto largo más bajos, casos de uso que antes eran prohibitivos ahora son viables. Pensemos en agentes de IA que puedan analizar y razonar sobre repositorios de código completos en tiempo real, asistentes legales que revisen miles de páginas de jurisprudencia instantáneamente, o sistemas de análisis financiero que procesen informes anuales completos en una sola pasada.
- Democratización del Poder: La eficiencia no solo beneficia a las grandes corporaciones. Un menor coste de entrenamiento y, sobre todo, de inferencia, permite que startups, desarrolladores freelance y empresas más pequeñas puedan acceder y desplegar modelos de vanguardia para crear soluciones a medida.
DeepSeek se consolida como un equipo que no solo persigue el rendimiento bruto, sino que aborda los problemas de ingeniería fundamentales que nos permitirán construir la próxima generación de aplicaciones de IA. Primero MoE, ahora DSA. Sin duda, hay que seguir manteniéndolos en el radar.
En última instancia, DeepSeek se consolida como un equipo que no solo persigue el rendimiento bruto, sino que aborda los problemas de ingeniería fundamentales que nos permitirán construir la próxima generación de aplicaciones de IA. Y es fascinante ver cómo esta carrera por la eficiencia, impulsada en parte por las restricciones de hardware impuestas a China por EEUU, está generando innovaciones en software que nos benefician a todos. Es la clásica historia de cómo la necesidad agudiza el ingenio, y en la carrera de la IA, el ingenio arquitectónico podría llegar a ser más decisivo que la fuerza bruta del silicio.
Primero MoE, ahora DSA. Sin duda, hay que seguir manteniéndolos en el radar.
Y tú, ¿qué opinas? ¿Cómo ves esto snuevos avances? ¡Deja tu comentario abajo!
Te dejo también el enlace a su carta en hugging face para que puedas investigar un poco más sobre este nuevo modelo.
